
Quality Matters, #5: Exceptions: The Worst Form of Error Handling, Apart From All The Others
by Matthew Wilson
This column instalment first published in ACCU's Overload, #98, August 2010. All content copyright Matthew Wilson 2010.
Abstract
The next two instalments of Quality Matters document another deconstructionist taxonomic journey into the essence of software development, the subject being exception handling. Along the way I consider arguments from both sides of the exception debate - those that think they're a curse, and those that think they're a godsend - and come to the not-entirely-unpredictable conclusion that exceptions are a curse and a godsend. To paraphrase Winston Churchill, exceptions are the worst form of 'error' handling, except for all the others.
I shall postulate that much of what is seen as wrong with exceptions arises from them being used for things for which they're unsuitable, albeit some of these misuses are necessary given the syntactic limitations imposed by some languages. I identify four types of actions/circumstances in which exceptions are used, suggest that only two of these are appropriate, and argue that we could all get a little more godsend and a little less curse if programmers, particularly language and library designers, would be more circumspect in their application of what is a very big hammer.
I consider some effects of exceptions on the intrinsic characteristics of software quality, in particular with respect to correctness/robustness/reliability [QM-2], and discoverability and transparency [QM-1]. I'll consider how exceptions affect other aspects - the (removable) diagnostic measures and applied assurance measures - in later instalments.
As by-products of this latest expedition into nomenclatural contrarianism, I rant lyrical about the abject mess that is .NET's near-unworkable definition and classification of exceptions, lament quizzical about Python's iterable mechanism, and wax nostalgic for the simplicity of C's (near) total absence of hidden flow-control mechanisms. I also have a go at the logical contradiction of C++'s logic_error exceptions, and, surprisingly - most surprising to me! - largely change my mind about Java's checked exceptions.
Introduction
Having dedicated all my scripting language attention to Ruby over the last five years, I'm currently refreshing my Python knowledge. I'm reading a nice book on Python 3, by an accomplished Python expert, published by a quality publisher. I'm not naming it, however, since I'm going to be criticising specific aspects of the book, rather than providing a proper review, and I don't want to negatively affect the sales of what is otherwise a good book. (It's blessed with a breadth and concision I've never achieved in any of my books so far!) Furthermore, some of the criticisms are of the language, rather than the book's examples or philosophy.
The problems I'm having with the book's content, and with Python itself, include:
- the use of subscript-out-of-range exceptions as a 'convenient' way of avoiding an explicit bounds check when accessing
sys.argv[1](see Listing 1, which is a much-simplified Python 2 equivalent) - the use of exceptions for 'regular' flow-control, e.g. synthesising three-level break semantics (in a case where a worker function would have been simpler and clearer)
- that iterators indicate (to the Python runtime) that they are complete by throwing an instance of
StopIteration.
Listing 1
import sys
try:
n = sys.argv[1]
y = int(n)
except IndexError:
print 'USAGE: Listing1.py <number>'
except ValueError, x:
print x, "in", n
There's actually nothing unequivocally wrong per se with the program in Listing 1. But I would never write code like that. (It may be that the author was being pedagogical and would never write code like that either, but that's not indicated in the text, so I am compelled to take him at face value as advocating this coding style.)
The code relies on IndexError being thrown if the user fails to specify a command-line argument, whereby sys.argv contains only the program name. I have two problems with this. First, such a situation could hardly be called an exceptional condition. It's not only anticipated, it's overwhelmingly likely to happen many times in the lifetime of such a program. Handling it as an exception at once muddies the waters from truly exceptional conditions (such as failing to be able to create a file), and also moves the handling of such an eventuality far away, in terms of the logical flow of a program, from where it is to be detected and, in my opinion, should be handled.
In a larger program, this would mean a large amount of code between the access(es) of sys.argv and the requisite catch clause. That would not be transparent, and would be very fragile to maintenance change. In a non-trivial program, you might imagine, as would I, that there would be many causes to issue a USAGE message. In which case, one would be likely to implement a separate consolidating usage() function (which may also call exit()). In such a case, it's hard to argue that catching IndexError is preferable to simply testing len(sys.argv).
The second issue is of much more moment. Exceptions such as IndexError are (if not wholly, then at least in part) used to detect mistakes on the part of the programmer. Coupled with the fact that almost any non-trivial program will contain multiple array indexed accesses, interpreting all IndexErrors to mean that the user has forgotten their command-line arguments is drawing a very long bow. (Strangely, the full example in the book does indeed contain multiple array accesses!)
If, as I hope, you agree that even this small example reveals, and is representative of, a troubling misapprehension as to the use of exceptions in programming, read on. If you don't, well, read on anyway, as I plan to change your mind.
In this instalment (and all subsequent instalments), I will be eschewing the use of 'error'. It is a term, like 'bug', that has been overloaded to the point of being more hindrance than help for discussing software behaviour. (There is a useful definition that will be introduced when we discuss contract programming, but it's probably not the one that tallies with most programmers' understanding. Until that time, any use of the term 'error' will be presented in quotes as a reminder that it's vague, unspecific, and largely unhelpful.)
Groundwork
In my own work I've experienced more than one bout of doubt about exceptions. In the next instalment, I'll describe three concrete cases to act as material for the discussion. Before that, though, I need to establish new terminology to deal with our 'error' issue. And before that, I'm going to establish some stereotypical positions that one encounters - some more than others - in the wider development community. And before that ... nope; just kidding.
Execution States and Actions
Every program has a purpose. Much of the intention and, usually, much of the programming effort is spent to define the program to achieve that purpose. It is reasonable to say that the purpose should accord with the intentions, and the expectations, of its users.
Consider the following four use scenarios of a word-processing program.
Scenario A: A user kicks off an instance of the program - the process - and waits for it to be loaded by the operating environment. Once it's loaded and ready to use, he/she writes some text, formatting as necessary until a point at which he/she decides to save or discard the work. We'll assume the choice is to save. The save is successful. The user closes the process. All that was intended to be done has been achieved. All is right with the world.
Scenario B: When the user elects to save the file-system rejects their request, due to perfectly reasonable causes: the disk is full, or they do not have the requisite permissions, or the network is down, and so on. What should the process do? Presumably we would like it to detect that the file cannot be written and take some action, rather than giving the tacit impression that all that was intended to be done has been achieved when that is not the case. That action might be to clear out any temporary files it was using to cache information, and retry. Alternatively, it might be to open a modal dialog and request that the user attempts to save to a different location. Either way, the process is not performing the program's main purpose, but it is reacting to anticipated non-main conditions in a planned fashion, in an attempt to get back to performing its main purpose.
Question 1: Does the inability to save the file constitute an 'error'?
Scenario C: Consider next that the user was able to save the document, but that in doing so it filled all but a few hundred kilobytes of the only disk available on the system. Assume that each instance of the program needs several megabytes of working storage available on disk to fulfil its undo, background-printing and other 'neat' features. The next time the user invokes a new process, which now finds itself unable to allocate the requisite disk space, what should it do? Presumably, we would like it to detect the condition and its cause, and inform the user of both, since he/she may/should be in a position to amend the situation, something that the process cannot be expected to do. It would be unsatisfactory to have the process silently fail, as the user would be left clicking new instances into life until the end of time (or at least until the end of his/her rag). It would also be unsatisfactory to have the process kick into seemingly good life, only to fail to save (in any form, anywhere) the user's work.
Question 2: Does the inability to allocate the working storage constitute an 'error'?
Scenario D: Consider, finally, that the program's author(s) failed to anticipate a certain condition, such as the user specifying a negative font size, whereupon the process's stack becomes corrupted, the process embarks on 'undefined behaviour', and the execution ends up who-knows-where (including, potentially, the document's disk file being overwritten with garbage and all work being lost).
Question 3: Does the failure to anticipate the negative font, and the consequent undefined behaviour, crash, and loss of work constitute an 'error'?
In this instalment I'm actually not interested in which, if any, of the three questions gets a Yes. We'll deal with that in a later instalment. (For the record, it's Question 3.) What I hope the distinct natures of the three questions illustrate is that answering Yes to any more than one of them -as many programmers would if asked each in isolation - does not make sense. Only one of them can get a Yes. And that's why the term 'error' is so problematic.
Additionally, we have a problem with describing the four types of behaviour of the program. There's the main-purpose bit, the can't-save-but-specify-another-place-and-carry-on-working bit, the can't-start-up bit, and the undefined-behaviour bit.
A New Vocabulary
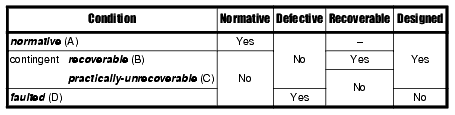
I suggest that we need a new vocabulary, and am (humbly?) proposing one here. With some help from the folks on the ACCU general mailing list, I propose the following precisely-defined terms: contingent; defective; faulted; normative; non-normative; recoverable; practically-unrecoverable. Each is derived in the following series of reductions, and the relationships are illustrated in the state diagram shown in Figure 1.
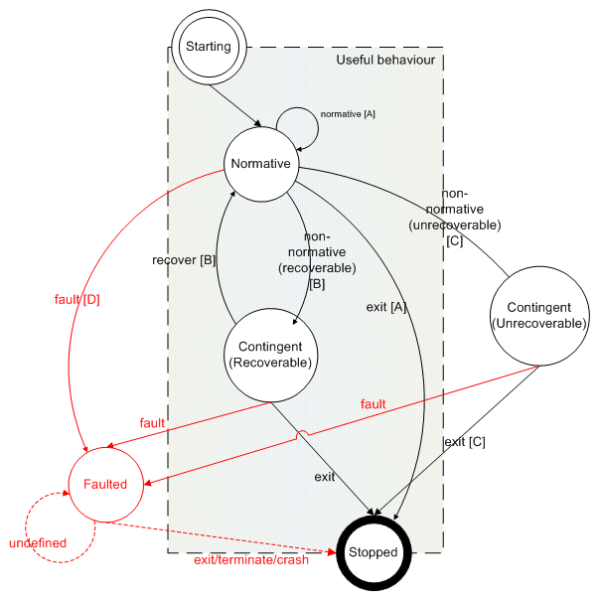
Normative behaviour is the main business of any piece of software, its raison d'étre, represented in Figure 1 by the transition from the Normative state to Normative state, via the normative action. Excepting the transitions from Starting and to Stopped, everything in scenario A is encapsulated within that single state and transition.
Rather obviously, everything that is not normative is non-normative. To properly understand non-normative action, and to use exceptions appropriately in accordance, we need two further reductions, delineating on the criteria of recoverability and defectiveness. All the reductions are shown in Table 1.
The difference between scenario A and the others is that, in scenarios B, C, and D, the user encountered a non-normative condition, one that is not a (desired) part of the functionality that is the main-business of the program.
Certainly, if systems could be created in which the saving of a file could never fail, or file-systems were perfectly reliable and had infinite storage capacity, that would be great. But since such things are impossible in practice, it's necessary to deal with contingencies (where possible). Experiencing such conditions is an inevitable part of just about every process, so the detection and handling of them is a vital part of software development.
The difference between scenarios B and C is that, in scenario B, the non-normative action could be handled in a way - for example, the user may select a different disk, or may delete some unwanted files to make space - that allowed the process to return to normative behaviour. In scenario C, it was not possible to achieve normative behaviour, and the process could not (be allowed to) continue.
I suggest that non-normative conditions that are recoverable (i.e. from which it is possible to get back to normative conditions) and the actions (such as opening a dialog, or deleting some temporary storage) that allow such recovery be termed recoverable. In Figure 1, this is represented by the transitions between the Normative and Contingent (Recoverable) states.
That just leaves us with discriminating between the behaviour of scenarios C and D, for which we need to consider the notion of defectiveness. As you will remember from part 2 [QM-2], an executing software entity can exist in three states: correct, defective, unknown. If a software entity exhibits behaviour that contradicts its design, then it makes the transition from unknown to defective. What's not yet been established (but will be in a forthcoming instalment) is that the transition to defective is a one-way trip, according to the principle of irrecoverability:
The Principle of Irrecoverability:
It is not possible for a software system to operate in accordance with its design if any component part of that system has violated its design.
Sticking with terminology that C/C++ programmers like, once a process has entered the realm of undefined behaviour, there's no way to get home. In Figure 1, this is evinced by only solid arrows leading into the Faulted state. The only arrows to emerge from the Faulted state, whence there's no guarantee of anything at all, not even of an eventual exit, are denoted by being dashed. I expect most of you, gentle readers, will have pertinent experiences as users and as programmers that attest to this uncertainty.
So, the crucial difference between the behaviour of scenarios C and D is not in terms of what the user is able to achieve with the process. In both cases the user cannot achieve anything useful with the process. (Or at least, we must hope that's true, since D can do anything, which could include appearing to behave in correct manner while silently deleting all the files on your system.) Rather, the difference is in what causes the unusability of the process.
In scenario C, this is caused by a runtime condition that can be experienced by a program operating in accordance with its design. In such cases, the failure to achieve a useful outcome is a result of the state of the operating environment, itself operating according to its design. There does not have to be anything wrong with either program or operating environment, it's merely a practical issue resulting from the confluence of their respective states and behaviours. After long (but ultimately fruitless) search for a better term, I suggest that this kind of non-normative condition be termed practically-unrecoverable. (I wanted to use the term fatal, but I fear it too has been associated with an ambiguous cloud of meanings pertaining to things stopping for a variety reasons, including faults. In any case, the chosen term reinforces the fact that it's a practical matter, usually involving a balance between exhaustion of finite resources and the amount of development effort to work around the finitude.)
It will be useful to refer to recoverable and practically-unrecoverable collectively. Since both involve contingent action (even if some of that is provided by the language runtime), I suggest the term contingent.
By contrast to scenario C, the unusability in scenario D arises from mistake(s) on the part of the software's author(s), either in the design, or in the reification of that design in the coding process. Since software does exactly what it's been programmed to do, if it's been programmed wrong, it is wrong. As I've already mentioned, I'll be dealing with the issue of software contracts, design violations, undefined behaviour, and so forth in a future instalment. For now, I'll restrict myself to simply defining the state of being defective as faulted. Whilst it's possibly easier to say/read, I rejected the term defective because it already has a meaning, and because it's possible for a process to be defective but never fault, if the defective part does not affect a given execution (in which case one might never know that it's defective).
I want to stress the point that in both recoverable and practically-unrecoverable execution, the program is reacting to conditions that have been anticipated in the design. The better the anticipation, and the more detailed and sophisticated the response, the higher the quality of the software when viewed from the perspective of the user-in-an-emergency. It is vital to recognise the significant point is not that such anticipation/response should be made, but that it can be made. Both recoverable and practically-unrecoverable conditions can be anticipated.
It's almost a tautology that for a condition to be recoverable, it must have been anticipated. But the anticipation does not have to be precise. In scenario B, it's possible to handle the general case of fail-to-save and use the associated information provided with the condition by the software component asked to perform the file operation, so long as appropriate information is provided. (This is where exceptions can have a significant advantage over return codes, if used well.)
In some cases where the condition has not been explicitly anticipated by the programmer, the language runtime may do that on his/her behalf. An obvious example is C++'s new operator throwing bad_alloc if it cannot fulfil the allocation request, which, if not caught, results in terminate() begin invoked, which causes the process to be terminated. Thus, the set of practically-unrecoverable conditions can comprise those that have been anticipated by the programmer of the software as well as those that have been anticipated by the language/library designer.
By contrast, conditions (marked 'fault' in Figure 1) that lead to the faulted state are those that do not constitute part of, and in fact contravene, the design. To hammer the point home I've denoted it in the 'Designed' column in Table 1.
Whose Concern(s)?
Normative behaviour is exhibited when your program encounters circumstances which your requirements and design designated as usual. Non-normative behaviour is exhibited when your program encounters circumstances which your requirements and design designated as unusual (or for which the requirements and design failed to account).
For obvious reasons, normative behaviour attracts the most focus. It is the prime concern of users, as is proper. It's also the major concern of project managers, requirements gatherers, business analysts, architects, and programmers, albeit that is a little less proper. When these disparate souls who band together to produce the software concern themselves exclusively, or even disproportionately, with normative behaviour, however, it's quite improper.
Non-normative actions, like insurance policies, the police, and a healthy immune system, are of little interest to most users until they find themselves in need of them. When they are needed, however, their worth multiplies enormously. (Philosophically speaking, this is one of the major causes of failure in software projects, though that's outside the scope of this instalment. I think it also explains what's wrong with democracy, but I'm way outside my remit here ...)
It is often the case that the judgement of the quality of a software product is disproportionately biased in favour of how well it deals with non-normative situations. (The reason I love FireFox so much is that, when it crashes - which it does a fair bit, though usually only when a certain Jobs'-vilified multimedia plug-in is getting a time slice - it knows the exact state of every tab in every window - and I have lots of tabs in lots of windows! - and restores them faithfully when next invoked.) Consequently, when viewed from the perspective of the programmer, the non-normative actions are very important indeed. In some senses, they're more important than the normative. But just as they are important, so they are also not well understood, nor well discriminated, particularly when it comes to the application of exceptions. Addressing this situation is the main thesis of these instalments.
Exception Use Stereotypes
Before we start looking at code, or picking at any particular language/library scabs, let's set the scene by stipulating some exception use stereotypes.
The exceptions-are-evil faction holds that exceptions are merely a slight, and inadequate, step-up from using goto for the handling of non-normative behaviour. One of the group's most famous members is Joel Spolsky, who (in)famously declared his colours in [SPOLSKY]. Though he copped cartloads of opprobrium - some suggesting he'd jumped the shark - for having the guts to put on record what concerns many, Spolsky identified two significant problems with the use of exceptions:
- they are invisible in the source code
- they create too many possible exit points
In my opinion, the two problems indicated amount to the same thing: exceptions break code locality. One of the attractions of C programming [!C^C++] is that, absent any use of longjmp() or any capricious use of fork() or exit()/_Exit()/abort()/raise(), it's possible to look at a sample of C code and understand its flow and, within the limitations of the given level of abstraction, its semantics for both normative and non-normative execution. Such is not the case in C++, C#, D, Java, Python, Ruby, or any of the other host of languages that rely on exceptions. When looking at code in such languages that is implemented in terms of other components, it is often difficult, even impossible, to understand the flow of control. This is a substantial detraction from transparency.
For my part, there is another important problem with the use of exceptions, which tends to get overlooked by most commentary:
- exceptions are quenchable
Regardless of the importance of a given exception, it is possible for any part of the calling code to catch it (and not rethrow it), thereby quenching what might have been a vital reporting of an unrecoverable condition. (The only exception of which I'm aware is .NET's ThreadAbortException.)
Spolsky's policy for exceptions is:
- never throw an exception
- catch every possible exception that might be thrown by a component in the immediate client code and deal with it
As with his objections to the use of exceptions, this policy contains some valuable nuggets of useful thought encapsulated within a horrifyingly-simplistic whole.
The exceptions-for-exceptional-conditions faction (as espoused in Kernighan and Pike's excellent The Practice of Programming [TPoP]) holds that exceptions should be used to indicate exceptional conditions (that fall within its design). In our terminology, this means that they should be used to indicate contingent conditions, but not for normative action.
The exceptions-for-normative-execution faction simply uses exceptions for any kind of programming they feel like. An example from the aforementioned Python book does exactly this. In order to effect a three-level break, a custom exception class is used.
The exceptions-for-fault-reporting faction holds that exceptions can be used for reporting contract violations (in addition to the other purposes already mentioned). Indeed, a number of languages and standard libraries adhere to this, including those of the C++ (logic_error), and Java (AssertionError) languages. Unfortunately, they are all wrong! Alas, once again I'm trespassing on the forthcoming contract programming instalment and trying your patience by teasing you with a controversial assertion without accompanying argument, but it can't be helped for now, as I'm running out of space and off the point.
The exceptions-are-broken faction don't trust their compiler to do the right thing when exceptions are thrown. Sometimes, they have a point.
The exceptions-are-slow faction can't use exceptions, due to performance (time and/or space) reasons, on real-time and/or embedded systems. They may be influenced in their views by the costs associated with the wholesale use of exceptions by the exceptions-for-normative-execution faction.
And the exceptions-won't-clean-up-after-me faction, populated by folks who don't know the techniques, like RAII, that can manage their resources expressively, with exception-safety, and make their code clearer.
Naturally enough, none of these positions is unalloyed wisdom, but that's enough groundwork. In the next instalment, I'll attempt to put flesh on the bones of the taxonomy, establish evidence for the recommendations I'm going to make, and illustrate the problems with each of the stereotypes, by discussing three of my own projects' exceptional issues.
What
All of the foregoing might have you wondering exactly what is an exception. (It did me.) Here's my parting thought on which you may cogitate until we meet again:
Exceptions are not an 'error'-handling mechanism. They are an execution flow-control mechanism.
We can say this because:
- the term 'error', if meaningful at all, does not represent the things for which exceptions are predominantly used under the nebulous umbrella of 'error-handling'
- it's possible, even if it's not wise, to use exceptions for flow-control of normative execution, something that no-one could ever claim to be 'error'
In this regard, exceptions are the same as returning status codes. Just a little less ignorable.
Acknowledgements
I'd like to thank Ric Parkin, the Overload editor, for his customary patience in the face of my chronic lateness and for small-but-essential suggestions of improvement, and my friends and, on occasion, righteously-skeptical review panel resident experts, Garth Lancaster and Chris Oldwood.
References
[!C^C++] !(C ^ C++), Matthew Wilson, CVu, November 2008
[QM-1] Quality Matters, Part 1: Introductions, and Nomenclature, Matthew Wilson, Overload 92, August 2009
[QM-2] Quality Matters, Part 2: Correctness, Robustness and Reliability, Matthew Wilson, Overload 93, October 2009
[SPOLSKY] http://www.joelonsoftware.com/items/2003/10/13.html
[TPoP] The Practice Of Programming, Brian Kernighanm, Rob Pike, Addison-Wesley, 1999