
Quality Matters, #3: A Case Study In Quality
by Matthew Wilson
This column instalment first published in ACCU's Overload, #94, December 2009. All content copyright Matthew Wilson 2009-2010.
Introduction
A few years ago I was tasked with the architecture/design and implementation of a suite of middleware daemons, to arbitrate between the external (point of sale) ingest lines and the processing cores, old and new, for a large Australian insurer. The system uses the AS2805 [AS2805] financial protocol, one of the more arcane and truculent data-exchange protocols I've had the pleasure of working with. It comprises variable-length fields, different character encodings (ASCII and EBCDIC) and Base-64 encoded data [BASE-64]. We hunted around for an open-source implementation of Base-64, but couldn't find anything that met our criteria, so I knocked one up. (Not on the client's time, of course.)
In this instalment, I'll be looking at the design and implementation of the resulting library, b64 [B64], and will also discuss changes I've been planning to make in light of matters arising in this column.
Base-64 encoding
Before we look at the library, let's first do a quick refresher on Base-64 encoding/decoding: I'm covering only the basics sufficient to be able to talk about the design of the library; if you want to know all the in-and-outs you'll have to do further reading.
As the name implies, Base-64-encoded data is encoded into 64-possible values from the range character range represented by the string
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
Each value, obviously, requires 6-bits to represent the value. Binary data is encoded in groups of three bytes, totalling 24-bits, into four Base-64 values. This may be shown pictorially (see Figure 1).
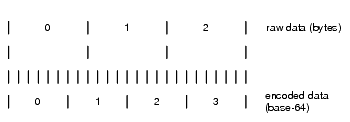
For example:
0x000000 // => "AAAA"
0x010000 // => "AAAB"
0x190000 // => "AAAZ"
0x330000 // => "AAAz"
0x3d0000 // => "AAA9"
0x3e0000 // => "AAA+"
0x3f0000 // => "AAA/"
0x400000 // => "AABA"
0x000001 // => "AQAA"
If the source data does not contain a multiple of three bytes, then one or two 0-bytes are used to pad out the last triple, and '=' characters used in the encoded output. For example:
0x0000 // => 0x000000 => "AAA="
0x0100 // => 0x000100 => "AAE="
0x00 // => 0x000000 => "AA=="
0x01 // => 0x000001 => "AQ=="
Perfection?
When I'm talking to developers about software quality, I often use b64 as an example of near perfection. It scores highly in all the following:
- correctness
- efficiency
- modularity
- portability
- discoverability (though with some deficiencies; discussed later)
- flexibility (in C++ API)
- expressiveness (in C++ API)
(In my opinion, it also scores well in transparency, but I cannot be sure that I'm not biased in that respect.)
Now, before you all accuse me of towering arrogance, I must point out that several of these are an almost inevitable consequence of the simplicity of the problem domain: these are credits by default, to be lost through haste or carelessness, rather than won by skill or insight. (There's also the not-inconsequential fact that I fluffed the first implementation by following too-old RFCs on Base-64 conversion, and so had to release a modified version that still bears the scars to this day; see sidebar.)
Nonetheless, it's a good little library, and its popularity, absent any serious effort at popularisation prior to this article, is justified, as is our looking at how and why it achieves its quality. Let's now consider each in turn, and discuss to what degree they're to be expected and what design decisions can influence their win/loss.
Design
The design of the library is informed by the following characteristics of Base-64 conversion:
- Given known input data size, the maximum required output data size can always be calculated accurately.
- The conversion to/from Base-64 format relies on a fixed, well-known algorithm that is entirely predictable, and free from any configuration or runtime influence.
These characteristics influence the design in several ways, including the implementation of the conversion algorithms, the library API, the way in which correctness (or robustness [QM-2]) will be assured, error indication/handling, even the choice of implementation language.
The main design features are:
- The implementation of the core library is in C; a C++ API is provided separately in header-only form
- The library functions do not allocate memory; it must be supplied by the caller
- No diagnostic logging is used in the library; quality is assured by automated testing and (optional) contract enforcement
Implementation language: C vs C++
The middleware suite was mainly C++, with a few modules written in C. All the parts that would touch Base-64 were C++. Despite this, I chose to implement it in C. As I've said before [!C^C++], absent any strong reasons in favour of C++ - such as the need to use containers in the implementation - I believe that C should be the default choice of implementation language. There are many reasons for this, dependent on the type of software entity being considered. In this case, the choice was based on portability and on need.
By implementing in C there's a modest advantage in portability. By presenting a C API, there's a considerable increase in the potential client applications and languages, including those written in C, C++, D, .NET, to name a few.
As far as need, there's just no clear (to me anyway) requirement to implement such conversion logic in C++. This may be because I have a bias against unnecessary use of C++, and prefer C APIs with C++ wrappers over pure C++ libraries whenever appropriate; if any readers can think of an advantage to writing b64 in C++ I'd be genuinely interested to hear it.
The choice of language has other impacts. One of the more obvious ones is that we don't have to worry about exceptions; we'll see how return codes are handled shortly.
Memory allocation
In cases where one may choose, the choice between having a library allocate memory and requiring users to provide memory depend on a number of factors, including:
- Whether the amount of memory to be used by the callee can be accurately predicted/determined by the caller
- For how long the memory may be required by the caller
This is also complicated by factors such as ensuring memory is allocated and released by the same memory pool/allocator [IC++].
In the case of Base-64 conversion, we've already noted that the amount of memory can be predicted by the caller based on the size of the data to calculate. The b64 API helps out here, in returning the maximum required size to the caller if they pass NULL for the destination to any encode/decode method (and does so in O(1)). Thus, in C, you might see a call sequence such as in Listing 1.
Listing 1
size_t n = b64_encode(src, srcLen, NULL, 0);
// get max required size
void* p = malloc(n);
. . . // handle allocation failure here
n = b64_encode(src, srcLen, p, n);
. . .
At face value, this complicates the life of the client coder: at least it appears to add more code. However, by removing memory allocation entirely from the library, the responsibilities are totally clear. And, even better, we can implement b64 entirely without dependencies on any other functions (including those of the standard library), which means that, discounting cosmic rays in the processor, its ability to perform its task correctly is dependent only on the code within.
Readers who managed to stay awake to the end of the last instalment should recognise the significance of this. When we factor in that Base-64 conversion is deterministic, and therefore highly amenable to automated testing, we realise that b64 is a software library for which we can demonstrate correctness (as opposed to robustness): a highly desirable characteristic of software.
(And, for C++ clients at least, we can and do provide useful, expressive wrappers that minimise/remove the intrusion on the transparency of client code, as I'll discuss later.)
Quality assurance
Although I have not (yet) heard of an application where Base-64 conversion is required to operate at MIP-blistering speed, it does seem kind of obvious that it shouldn't have much fat in it. Consequently, one original design decision - still upheld in my recent updates - is that it should not have diagnostic logging. Of course, performance is not the only, or even the most significant, factor in determining whether a software entity should include diagnostic logging. (And if you believe the propaganda of, er, me - in respect of the Pantheios diagnostic logging API library, anyway - you don't even need to sacrifice performance to have logging statements compiled into released code. But that's for another day ...)
Back on point: the major factor at play here is that the algorithms are self-contained and deterministic. For a given input, we must have a given output, regardless of whether we're running on a mainframe, Windows PC, Linux quad-core server, iPhone, whatever. Adding diagnostic logging is simply a waste of time here, because the diagnostic logging that will be in the application in the code that calls into b64 will be sufficient to (i) record its failure, and (ii) record the precipitating input data; the latter can be replayed into the library at any later time to test the veracity of the expected result.
The b64 C API
The b64 C API consists of two enumerations and six functions, enclosed (in C++ compilation) in the b64 namespace. Listing 2 shows a truncated form of the b64/b64.h header, including all the essential elements.
Listing 2
/* b64/b64.h */
#include <stddef.h>
#if !defined(B64_NO_NAMESPACE) && \
!defined(__cplusplus)
# define B64_NO_NAMESPACE
#endif /* !B64_NO_NAMESPACE && !__cplusplus */
#ifndef B64_NO_NAMESPACE
namespace b64
{
#endif /* !B64_NO_NAMESPACE */
typedef char b64_char_t;
enum B64_RC
{
B64_RC_OK
, B64_RC_INSUFFICIENT_BUFFER
, B64_RC_DATA_ERROR
};
#ifndef __cplusplus
typedef enum B64_RC B64_RC;
#endif /* !__cplusplus */
enum B64_FLAGS
{
B64_F_LINE_LEN_USE_PARAM = 0x0000
, B64_F_LINE_LEN_INFINITE = 0x0001
, B64_F_LINE_LEN_64 = 0x0002
, B64_F_LINE_LEN_76 = 0x0003
, B64_F_LINE_LEN_MASK = 0x000f
, B64_F_STOP_ON_NOTHING = 0x0000
, B64_F_STOP_ON_UNKNOWN_CHAR = 0x0100
, B64_F_STOP_ON_UNEXPECTED_WS = 0x0200
, B64_F_STOP_ON_BAD_CHAR = 0x0300
};
#ifndef __cplusplus
typedef enum B64_FLAGS B64_FLAGS;
#endif /* !__cplusplus */
#ifdef __cplusplus
extern "C" {
#endif /* __cplusplus */
size_t b64_encode(
void const* src
, size_t srcSize
, b64_char_t* dest
, size_t destLen
);
size_t b64_encode2(
void const* src
, size_t srcSize
, b64_char_t* dest
, size_t destLen
, unsigned flags
, int lineLen /* = 0 */
, B64_RC* rc /* = NULL */
);
size_t b64_decode(
b64_char_t const* src
, size_t srcLen
, void* dest
, size_t destSize
);
size_t b64_decode2(
b64_char_t const* src
, size_t srcLen
, void* dest
, size_t destSize
, unsigned flags
, b64_char_t const** badChar /* = NULL */
, B64_RC* rc /* = NULL */
);
char const* b64_getErrorString(B64_RC code);
size_t b64_getErrorStringLength(B64_RC code);
#ifdef __cplusplus
} /* extern "C" */
#endif /* __cplusplus */
#ifndef B64_NO_NAMESPACE
} /* namespace b64 */
#endif /* !B64_NO_NAMESPACE */
There are several aspects to note:
- The API has include-dependency only on stddef.h, which will be available on every compiler you come across.
- If compiling for C, the namespace is suppressed. Otherwise, unless
B64_NO_NAMESPACEis defined, all elements will be within theb64namespace, according to best practice. - The
b64_char_ttypedef is used in case a widestring port will ever be required. (This hasn't come up yet.) B64_RCis a value enumeration, representing result codes;B64_FLAGSis a flags enumeration, used for moderating the behaviour of encoding/decoding. The use of typedefs on the enumeration names ensures that the same names are available in C and C++, and the qualifying prefix enum is not required in C [!C^C++].- The 2-variants cater to the needs of the RFC specifications in working with newline-split input/output encoded sequences.
- The aforementioned mistake is evident in the presence of
b64_encode()/b64_decode(), which are actually implemented in terms of the corresponding 2-variants. More seriously, it means that the return type of the 2-variants serves double duty, indicating the number of elements (to be) converted and, by returning 0, that an error may have occurred, in which case the caller must check the out-parameter rc. Although we'll see later that with the C++ API implementation that this becomes unimportant, it is nonetheless a detraction from discoverability for users of the C API. (-1 point here.) - Conversion of
B64_RCto string form (and length thereof) are provided for usingB64_RCwith a diagnostic logging library (such as, er, Pantheios); see [STRERROR] for details of how this works.
Let's briefly examine my claims regarding the software quality characteristics, before we move on to consider the implementation and the C++ API.
Correctness
This is established by automated tests, which come with the library and are built and executed by "make test".
Efficiency
Strangely, for me, I've never actually tested its performance. Since it allocates no memory, uses static lookup tables for converting between encoded and unencoded form, and doesn't do anything more than once, I've simply assumed that it has good performance. Were performance a major criterion, or had anyone ever reported an issue, I guess I would do so, but absent that, why bother?
Modularity
Here's where b64 rises above just about any other non-trivial library: it has 100% modularity in a release build; in debug form it relies on the runtime's assert() support and a couple of string functions. Obviously, the acclaim for this is largely due to the characteristics of the problem area, which then enable the choice to eschew memory allocation.
Portability
The implementation relies only on the standard headers string.h and assert.h (in addition to b64/b64.h), so we can also claim that b64 also has near perfect portability. In this case, it is a by-product of the problem area; one would have to try hard to introduce non-portability. The only non-portable aspect is the use of English result code strings, but this is not a true break of localisation, as discussed in [STRERROR].
Expressiveness
The C API does no better or worse in terms of expressiveness than any such API could, which is to say not very much. As we'll see shortly, expressiveness is dealt with in the C++ API, commensurate with the (my, anyway) hypothesis that the major reason people choose C++ over C (or any one language over another) is expressiveness.
Flexibility
The C API is not flexible at all, since few C APIs are able to offer any bona fide flexibility, and those that do - e.g. the variadics - tend to be inherently unsafe. Again, the C++ API takes care of flexibility.
Discoverability
Other than the result-code-as-out-parameter ugliness already discussed, I contend that the API is largely discoverable. Ignoring the extensive per-function documentation (not shown), the API functions are self-documenting in the following ways:
- The enumerators for both enumerations are pretty self-explanatory. A function might succeed, or fail due to insufficient buffer or data error (i.e. asking
b64_decode2()to decode arbitrary text data consisting of non-Base-64 characters). Encoding line length can be a fixed infinite (no newline), 64 or 76, or a user specified length. Decoding can be asked to stop on an unknown character, and/or on unexpected whitespace, or simply ignore bad characters and proceed. -
The encoding/decoding functions represent input and output memory ranges as matched pairs of length+pointer. This leaves only three parameters to grok.
flagsshould be obvious: a combination ofB64_FLAGS.rcis an optional (as denoted by the comment) pointer to a variable to receive the return code.badCharis an optional (as denoted by the comment) pointer to a (non-mutating) pointer to a character, which will be set to refer to the bad character that stops the decoding.lineLenspecifies the required maximum line length, but will be ignored unless
B64_F_LINE_LEN_USE_PARAM == (flags & B64_F_LINE_LEN_MASK)
The things you can glean only from the documentation are:
- If you specify a
lineLenof less than 0 (whenB64_F_LINE_LEN_USE_PARAM == (flags & B64_F_LINE_LEN_MASK)), the line length defaults to 64. - If you specify a
lineLenof 0, you get an infinite line length. - If you specify
NULLfordest, the function returns the maximum possible amount of memory (characters or bytes) required.
Transparency
In the previous instalment [QM-2] I gave a sample of the implementation of b64_encode2(), from which you may make your own judgements. In researching this instalment I had occasion to go back and try and understand the implementation. Since the last modification of any significance was done nearly a year ago, I therefore experienced the transparency anew. Acknowledging a few minutes to acclimatise, I was able to find my way pretty well. Of course, transparency is a very subjective thing - coding styles (layout, naming), choice of idioms, and so on all influence - and I'm the author! It's quite conceivable you might not find the implementation transparent and the only thing I can say for certain is that it's one of the more transparent implementation that I've written.
The b64 C++ API
I don't have space here to include the full implementation of the library. As mentioned above, the essential elements from b64_encode2() were shown in the last instalment [QM-2]; and you can download the library to look at it if you wish. In any case it's not really necessary. Given the design decisions and the API outlined above, I think any competent C programmer could produce a correct, portable, efficient and (reasonably) transparent implementation.
What I think is of interest is in how the low-level C API can be mapped into C++ with a good dose of expressiveness and flexibility. In my opinion, the biggest issue C++ users will have with the C API are:
- The need to manually manage memory
- The abstraction dissonance [QM-1, Monolith] encountered when having to work with 'raw' types such as ranges of characters and bytes
Both of these are exemplified by what I consider would be the common types - std::string and std::vector<unsigned char> - and preferred usage patterns of the library in C++ code:
typedef std::vector<unsigned char> bytes_t; bytes_t raw = . . . // read in from somewhere std::string encoded = AcmeBase64::encode(raw);
b64's C API cannot support this. Instead, the user will be forced to write something along the (possibly pseudo-code) lines in Listing 3.
Listing 3
b64::B64_RC rc;
size_t n = b64::b64_encode2(&raw[0]. raw.size(), NULL, 0, 0, 76, &rc);
if(0 == n && b64::B64_RC_OK != rc)
{
throw std::runtime_error(b64::b64_getErrorString(rc));
}
std::string encoded;
encoded.reserve(n);
// don't lose "buff" in an assign()-throw
char* buff = new char[n];
n = n = b64::b64_encode2(&raw[0], raw.size(), buff, n, 0, 76, &rc);
encoded.assign(buff, n);
delete [] buff;
Truly hideous stuff. Thankfully, b64's C++ API does not require this of the poor programmer. Consider the simplified listing of b64/b64.hpp in Listing 4.
Listing 4
#include <b64/b64.h>
#include <stlsoft/stlsoft.h>
#if defined(B64_USE_CUSTOM_STRING)
# include B64_CUSTOM_STRING_INCLUDE
#else /* B64_USE_CUSTOM_STRING */
# include <string>
#endif /* !B64_USE_CUSTOM_STRING */
#if defined(B64_USE_CUSTOM_VECTOR)
# include B64_CUSTOM_VECTOR_INCLUDE
#else /* B64_USE_CUSTOM_VECTOR */
# include <vector>
#endif /* !B64_USE_CUSTOM_VECTOR */
#include <stlsoft/memory/auto_buffer.hpp>
#include <stlsoft/shims/access/string.hpp>
#include <stdexcept>
#ifndef B64_NO_NAMESPACE
namespace b64
{
#endif /* !B64_NO_NAMESPACE */
class coding_exception
: public std::runtime_error
{
public:
coding_exception(B64_RC rc, char const* badChar);
public:
B64_RC get_rc() const;
char const* get_badChar() const;
private:
B64_RC m_rc;
char const* m_badChar;
};
#if defined(B64_USE_CUSTOM_STRING)
typedef B64_CUSTOM_STRING_TYPE string_t;
#else /* B64_USE_CUSTOM_STRING */
typedef std::string string_t;
#endif /* !B64_USE_CUSTOM_STRING */
#if defined(B64_USE_CUSTOM_VECTOR)
typedef B64_CUSTOM_BLOB_TYPE blob_t;
#else /* B64_USE_CUSTOM_VECTOR */
typedef std::vector<unsigned char> blob_t;
#endif /* !B64_USE_CUSTOM_VECTOR */
inline string_t encode(void const* src, size_t srcSize, unsigned flags, int lineLen = 0, B64_RC* rc = NULL)
{
typedef stlsoft::auto_buffer<char, 1024> buffer_t;
B64_RC rc_;
if(NULL == rc)
{
rc = &rc_;
}
size_t n = b64_encode2(src, srcSize, NULL, 0, flags, lineLen, rc);
buffer_t buffer(n);
size_t n2 = b64_encode2(src, srcSize, &buffer[0], buffer.size(), flags, lineLen, rc);
string_t s(&buffer[0], n2);
if( 0 != srcSize &&
0 == n2 &&
rc == &rc_)
{
throw coding_exception(*rc, NULL);
}
return s;
}
inline string_t encode(void const* src, size_t srcSize)
{
return encode(src, srcSize, 0, 0, NULL);
}
template <typename T, size_t N>
inline string_t encode(T (&ar)[N])
{
return encode(&ar[0], sizeof(T) * N);
}
inline string_t encode(blob_t const &blob)
{
return encode(blob.empty() ? NULL : &blob[0],
blob.size());
}
inline string_t encode(blob_t const &blob, unsigned flags, int lineLen = 0, B64_RC* rc = NULL)
{
return encode(blob.empty() ? NULL : &blob[0], blob.size(), flags, lineLen, rc);
}
inline blob_t decode(char const* src, size_t srcLen, unsigned flags, char const** badChar = NULL, B64_RC* rc = NULL)
{
B64_RC rc_;
char const* badChar_;
if(NULL == rc)
{
rc = &rc_;
}
if(NULL == badChar)
{
badChar = &badChar_;
}
size_t n = b64_decode2(src, srcLen, NULL, 0, flags, badChar, rc);
blob_t v(n);
size_t n2 = v.empty() ? 0 : b64_decode2(src, srcLen, &v[0], v.size(), flags, badChar, rc);
v.resize(n2);
if( 0 != srcLen &&
0 == n2 &&
rc == &rc_)
{
throw coding_exception(*rc, (badChar == &badChar_) ? *badChar : NULL);
}
return v;
}
inline blob_t decode(char const* src,
size_t srcLen)
{
return decode(src, srcLen, 0, NULL, NULL);
}
template <class S>
inline blob_t decode(S const& str)
{
return decode(stlsoft::c_str_data_a(str), stlsoft::c_str_len_a(str));
}
inline blob_t decode(string_t const& str, unsigned flags = 0)
{
return decode(stlsoft::c_str_data_a(str), stlsoft::c_str_len_a(str), flags, NULL, NULL);
}
inline blob_t decode(string_t const& str, unsigned flags, char const** badChar, B64_RC* rc = NULL)
{
return decode(stlsoft::c_str_data_a(str), stlsoft::c_str_len_a(str), flags, badChar, rc);
}
#ifndef B64_NO_NAMESPACE
} /* namespace b64 */
#endif /* !B64_NO_NAMESPACE */
Once again, there are several points to note:
- The API function names reflect the fact that they're inhabiting the
b64namespace, and dispense with theb64_-prefix of the C API. Users now write the clearly digestibleb64::encode()andb64::decode(). - The API raises the level of abstraction and deals with strings and "blobs" (sequence of bytes), rather than size+pointer pairs.
- The units of currency for string and "blob" types are assumed, respectively, to be
std::stringandstd::vector<unsigned char>. But it's flexible in two ways. First, custom types may be specified at compile-time, via definition of the appropriate pre-processor symbols, for string and/or blob. Second, the use of string access shims [IC++, XSTLv1, FF-2] means thatb64::decode()may be called on instances of arbitrary string types - Memory allocation is handled within the C++ API entirely, so users need neither concern themselves with (de-)allocating the memory nor detecting failure to allocate it (at the level of their client code).
- The library reports coding errors via exceptions if users elect not to receive the errors (by passing an address of a
B64_RCvariable). - The functions handle all the issues of standards conformance, such as the fact that one cannot invoke the subscript operator on an empty
std::vector, nor assume the contiguity of storage instd::string. Such things have a habit of leaking from one's (sub-)conscious onto the screen, as actually just happened to me in the pseudo-code at the start of this section! - On reflection, the inclusion of the literal array overload of
encode()is probably gratuitous; more "look what I can do" than "we need this". However, if anyone can think of a real scenario for this, please let me know.
I contend that the discoverability of these C++ API functions is good, and that the transparency is also reasonably good (assuming one understands the notion and purpose of string access shims). But where it really shines is in the modest increase in flexibility and the substantial increase in expressiveness. We can now write code such as Listing 5 and Listing 6.
Listing 5
unsigned char bytes0[] = { 0, 1, 2, 3, 4, 5, 6, 7, 8 9 };
void* bytes1 = . . .
size_t n1 = . . .
b64::blob_t bytes2 = . . . // blob_t aka std::vector<unsigned char>
b64::string_t encoded0 = b64::encode(bytes0); // string_t aka std::string
b64::string_t encoded1 = b64::encode(bytes1, n1);
b64::string_t encoded2 = b64::encode(bytes2);
Listing 6
char encoded0[] = { 'A', 'A', 'A', 'A' };
std::string encoded1("AAE=");
char const* encoded2 = "AQAA";
b64::blob_t decoded0 = b64::decode(encoded0, 4);
b64::blob_t decoded1 = b64::decode(encoded1);
b64::blob_t decoded2 = b64::decode(encoded2);
New 'software quality' changes
When, some months ago, I'd planned an instalment of this column that would discuss b64, I'd planned to include an evolution of the library implementation to include the (removable) diagnostic measures [QM-1]:
- Code Coverage, via the xCover library [XCOVER]
- Contract Enforcement, via the xContract library
However, now I've got this far, I realise that I shouldn't bother. This is not, as the Overload editorial team may suspect, due to the fact that I've overrun the submission deadline for the third instalment in a row. Rather, it's because I realise that neither of these measures are necessary for b64. (I warned you when we started that this is a learning experience for me as well.)
First, the code coverage. The implementation of encoding has three branches and four loops. Decoding has nine branches and one loop. Although nine could be argued as a decent amount of complexity, it's the case that each branch (and loop) can be determined by visual inspection to be part of behaviour already established (by testing) as correct. Now, it's presumption bordering on hubris to say 'the requirements' won't change, or 'my project's not complex enough to need [insert useful software quality assurance technique requiring a modicum of effort here]'. So I won't claim either of those. What I will claim, however, is that, given the library has a pretty comprehensive test suite and has been in use for several years without a report of defective conversion, it's not worth the cost of introducing code coverage. As well as introducing coupling to other (admittedly open-source, and bundleable) libraries, it also introduces more choices to users of the libraries, and choice is the enemy of discoverability. Furthermore, it'd also mean more effort for me in teasing out a bit more sophistication from my already moribund, kill-yourself-rather-than-change-anything, ripe-for-rewrite makefile generator.
Things are a little less clear cut with contract enforcement. The library already has contract enforcement implemented in the 'usual way', which is to say via the C standard library's assert() macro. For sure, this only applies in debug builds, but contract enforcement is a removable diagnostic measure, so that's perfectly legitimate. It's not always the wisest choice to elide contract enforcements from release builds; I'll cover this a future instalment of the column, dedicated to contract programming principles and practice. But in this case, I'm again inclined to live with the status quo for the same reasons as for code coverage:
- b64 has a lot of tests
- it has an established history of correctness
- I don't want to burden users with more choices / build hassles
- I don't want to burden myself with more work for no tangible benefit
It may seem a little perverse to be writing a column about the practical application of software quality assurance measures, and then not actually apply any. But we're talking about removable diagnostic measures, and perhaps it's useful to start out by abstinence just to ram the removability point home.
But fear not, earnest fellow appliers of software quality measures, these things will soon be introduced to a library near you! In fact, for all the reasons that b64 does not qualify for the various (removable) diagnostic measures - logging, code coverage, contract enforcement - I have a library that needs them for the same reasons: recls. I've recently released the first 100%-X rewrite - a 100% .NET implementation [RECLS100.NET] - and am also planning to release a reworked version of the main C/C++ library very soon. So, the next instalment will probably contain an examination - theoretical and practical - of how I go about adding diagnostic measures to recls in C and C++.
References and asides
[AS2805] http://en.wikipedia.org/wiki/AS_2805
[BASE-64] http://wikipedia.org/wiki/Base64
[B64] http://synesis.com.au/software/b64/
[!C^C++] !(C ^ C++), Matthew Wilson, CVu, November 2008
[IC++] Imperfect C++, Matthew Wilson, Addison-Wesley, 2004
[Monolith] http://breakingupthemonolith.com/
[QM-1] Quality Matters, Part 1: Introductions, and Nomenclature, Matthew Wilson, Overload 92, August 2009
[QM-2] Quality Matters, Part 2: Correctness, Robustness and Reliability, Matthew Wilson, Overload 93, October 2009
[RECLS100.NET] recls 100% .NET, Matthew Wilson, Dr Dobb's Journal, November 2009
[STRERROR] Safe and Efficient Error Information, Matthew Wilson, CVu, July 2009